

Yapay Zeka ve Makine Öğrenmesi 2025 Vize
Bu vize sınavı; yapay zeka ve makine öğrenmesinin temel kavramlarını (danışmanlı/danışmansız öğrenme), veri tiplerini (sıralı, ayrık, nominal), veri ön işleme adımlarını (ayrıklaştırma, dummy kodlama, eksik veri doldurma), makine öğrenmesi algoritmalarının çalışma mantığını (k-Ortalamalar) ve Python ile veri görselleştirme/analiz (Seaborn, Matplotlib, Pandas describe() metodları) konularını kapsamaktadır.
Sınavda Hangi Konular Var? (Özeti Görmek İçin Tıkla ⬇️)
MAKİNE ÖĞRENMESİ konulu sınav/doküman özeti aşağıdadır:
Yapay Zekâ ve Makine Öğrenmesi Kavramları
- Günümüz yapay zekâ çalışmaları, üretken yapay zekâ (Generative AI) olarak adlandırılmaktadır.
- Üretken yapay zekâ sistemlerine örnek olarak farklı grafik/illüstrasyon oluşturan sistemler, daha önce mevcut olmayan bir şarkı, ses efekti ya da ses kaydı oluşturan sistemler, rastgele resim üreten sistemler ve otomatik metin oluşturan sistemler gösterilebilir. Kullanıcı etkileşimlerini analiz eden bir veri tabanı yönetim sistemi üretken yapay zekâ örneği değildir.
- Makine öğrenmesinin temel unsurları Görev, Algoritma, Deneyim (veri) ve Performans’tır. Analizde kullanılan programlama dili bu unsurlardan biri değildir.
- Tipik bir makine öğrenmesi modeli bileşenleri; kullanılan makine öğrenmesi algoritmasına ait parametreler, makine öğrenmesi algoritması, nitelikler ve eğitim verisidir. Veri setinde iki sürekli niteliği görselleştirmede kullanılan Python kodu bir bileşen değildir.
- Makine öğrenmesi stratejilerinden biri Danışmanlı öğrenmedir.
Makine Öğrenmesi Stratejileri ve Algoritmaları
- Danışmanlı öğrenmede veri setinde bir hedef niteliğin bulunmasına ihtiyaç duyulur. Bu strateji ile Sınıflandırma problemleri çözülebilir.
- Danışmansız öğrenme, Boyut azaltma ve Kümeleme gibi görev türlerini kapsar. Bir şirket, danışmansız öğrenme algoritmalarından faydalanarak müşterilerini kümelere ayırabilir.
- Pekiştirmeli öğrenme, ödül-ceza prensibine dayalıdır ve ajan, çevre, eylem gibi kavramlarla ilişkilidir.
- k-Ortalamalar Algoritması: Müşterileri alışveriş alışkanlıklarına göre kümelemek için uygundur. Python kodunda
KMeans(n_clusters=5, ...)ifadesi, k-Ortalamalar algoritmasının Küme Sayısı=5 parametresi ile kullanıldığını gösterir. - Verilen küme merkezleri tablosunda, (3,6) örnek verisi en yakın olan Küme 2’ye (Küme Merkezi: (2,5)) atanır.
Veri Türleri ve Ön İşleme
- Sıralı kategorik veriye örnek olarak “Küçük – orta – büyük” verilebilir.
cagrilar(aramaların sayısı: 500, 750, 1000, …) niteliğinin veri tipi için en uygunu Ayrık’tır.- Maaş gibi sürekli nitelikleri kategorik hale getirmek için Veri ayrıklaştırma yöntemi kullanılabilir.
evSahipligi(Var, Yok) gibi kategorik nitelikteki eksik veriyi (?) tamamlamak için nitelikteki sayıca en fazla olan kategori eksik veri yerine atanabilir.- Yapay (dummy) kodlama kullanılan tabloda, 04 numaralı örnekte tüm kahve türleri 0 olduğu için, Americano, Cappuccino, Latte, Türk Kahvesi dışındaki kahve türü olan Mocha‘dır.
Veri Görselleştirme ve Analiz
Kontenjans Tablosu: Verilen tabloda, doğru tahmin edilen Düşük risk grubundaki müşterilerin sayısı 10’dur (TAHMİN Düşük ve GERÇEK Düşük kesişimi).
Bir Pandas DataFrame olan musteri adlı veri setinin özet bilgisini görüntülemek için musteri.describe() seçeneği kullanılır.
Histogramlar: Sürekli nitelikler için çizimi uygundur. Niteliklerin simetrik dağılıma sahip olup olmadığı veya sağa/sola çarpık olup olmadığı görülebilir. Histogramlar iki nitelik arasındaki pozitif ve negatif yönlü ilişkileri ortaya koymaz.
Grafik çizimi: sns.histplot(data=veri, x="sepal_length") kodu, x ekseninde sepal_length niteliği ve y ekseninde Count ile gösterilen histogram grafiğini (sütun grafiği) çizer.
Aykırı değerler, Kutu grafiğinde görülebilir.
Bir sütun grafiğinin yatay biçimde oluşturulmasını sağlayan Python fonksiyonu plt.barh()‘dir.
Sonuçlar
#1. Günümüzdeki yapay zekâ çalışmaları üretken yapay zekâ (Generative AI) olarak adlandırılmaktadır. Aşağıdakilerden hangisi üretken yapay zekâ sistemlerine örnek gösterilemez?
#2. Aşağıdaki görevlerin hangisini k-Ortalamalar Algoritmasını kullanarak gerçekleştirmek daha uygundur?
#3. Aşağıdakilerden hangisi tipik bir makine öğrenmesi modeli bileşenlerden biri değildir?

#4. Küme Merkezi Küme Küme 1 (0.06 0.5) Küme 2 (2 5) Küme 3 (7 8) Küme 4 (10 15) Küme 5 (60 70) k-Ortalamalar algoritması kullanılarak gerçekleştirilen kümeleme sonucunda elde edilen kümeler ve küme merkezleri yukarıdaki tabloda verilmiştir. Buna göre örnek veri (3 6) hangi kümeye benzerlik gösterir ve atanır?
#5. Aşağıda verilen görev türlerinden hangisi danışmansız öğrenme kapsamına girmez?

#6. Python kumeSayisi=3 model = KMeans(n_clusters=5 init=”k-mean s++” n_init=”auto” random_state=7) Yukarıda verilen Python kodlarını çalıştıran bir araştırmacı hangi algoritmayı ve bu algoritma için aşağıdaki hangi parametreyi kullanıyor olabilir?
#7. Histogramlarla ilgili aşağıda verilen bilgilerden hangisi yanlıştır?
#8. Aşağıdaki seçeneklerden hangisindeki Python fonksiyonu bir sütun grafiğinin yatay biçimde oluşturulmasını sağlar?
#9. Aşağıdaki seçeneklerden hangisi makine öğrenmesinin temel unsurları arasında yer almaz?
#10. Aşağıdakilerden hangisi makine öğrenmesi stratejilerinden biridir?
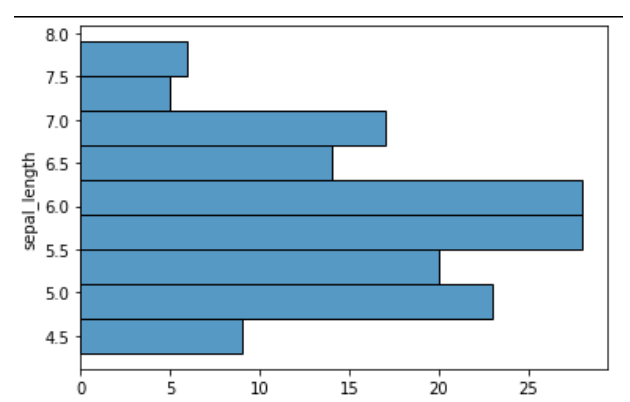
#11. Yukarıda verilen grafiğin çizilebilmesi için aşağıdaki seçeneklerden hangisi kullanılmalıdır?
#12. Aşağıda verilen grafik türlerinden hangisinde bir niteliğe ait aykırı değerler görülebilir?
#13. Aşağıdakilerden seçeneklerden hangisinde sıralı kategorik veriye örnek verilmiştir?
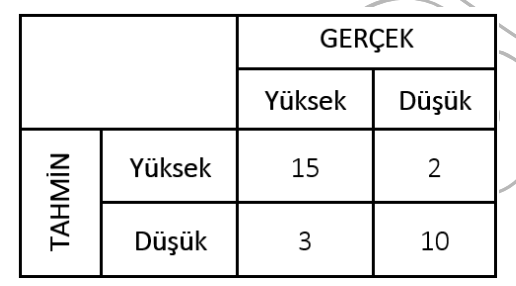
#14. Yukarıda verilen kontenjans tablosuna göre doğru tahmin edilen “Düşük risk” grubundaki müşterilerin sayısı aşağıdaki seçeneklerden hangisinde doğru biçimde verilmiştir?
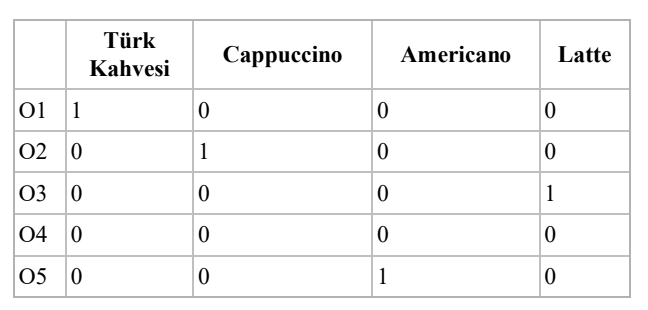
#15. Türk Cappuccino Americano Latte Kahvesi O1 1 0 0 0 O2 0 1 0 0 O3 0 0 0 1 O4 0 0 0 0 O5 0 0 1 0 Tabloda kahve örneklerinin (O1 O2 O3 O4 ve O5) kahveTuru niteliği yapay (dummy) kodlama kullanılarak verilmiştir. kahveTuru niteliğinde Americano Cappuccino Latte Mocha ve Türk Kahvesi çeşitleri bulunmakta olup örnekler verilen kahve türlerinden yalnızca birine aittir. Yukarıda verilenlere göre Örnek 4’ün (O4) kahveTuru aşağıdakilerden hangisidir?
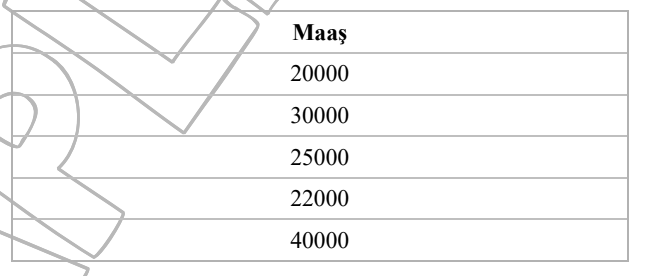
#16. Maaş 20000 30000 25000 22000 40000 Yukarıda verilen Maaş niteliğinin kategorik hale getirilebilmesi için aşağıda verilen yöntemlerden hangisi kullanılabilir?
#17. Bir Pandas DataFrame olarak verilen musteri adlı veri setinin özet bilgisini görüntülemek için aşağıdaki seçeneklerden hangisi kullanılabilir?
#18. Makine öğrenmesi stratejileri ile ilgili aşağıdakilerden hangisi yanlıştır?
#19. cagrilar: Bir bankanın çağrı merkezine gelen aramaların sayısı (500 750 1000 …). cagrilar niteliğinin veri tipi için aşağıdaki seçeneklerden hangisi en uygundur?
